JavaScriptプログラマのための2019年の機械学習と関数型プログラミング
この記事では、TensorFlow.js界隈について個人的に俯瞰した内容をシェアしています。
1. ちゃぶ台返しの世界
前回のエントリ JavaScriptによる機械学習の未来(TensorFlow.js)と関数型プログラミングでは、あたかもJavaScriptによる機械学習の未来がTensorFlow.jsの登場により明るい、という論調で書きましたが、この記事ではちゃぶ台返しをします。
昨今のJavaScript界隈を見ても進化が目まぐるしくて、完全にデファクトスタンダードになったと思っていた技術を習得して、しばらくは安泰だな・・・と思っていたら、ちょっとボケっとしてる間に突然変異を起こした別のフレームワークの登場によりあっという間に自然淘汰が現在進行系というのは日常茶飯事。
脱jQueryからのReactは言うに及ばず(2015年にたしか、「ReactになるからjQueryはもう使わない」とか半ば強い主張をしたとき猛烈に反発してきた人もいた)、browserifyからのwebpackからのParcelだったり、そもそもESM使え、だったり、npmじゃなくてyarnを使おうとなったり、まあかなりJavaScriptには密にコミットしているつもりの自分ですら、ちゃぶ台返しされすぎてわけがわからなくなるときがあります。
JavaScriptによる機械学習の未来(TensorFlow.js)と関数型プログラミングが明るい、というのは、3-5年のダイナミズムを考えればあながちなち間違っていないのかもしれません。しかし、少なくとも2019年にヘビーにコミットしてしまうのは、コスパ悪い、と言うのが今回の主張です。
Python完全支配下の機械学習界隈も、3-5年のダイナミズムを考えるとJavaScriptにあっさりちゃぶ台返しされてしまうかもなあ、と思いつつも、そこを先物買いして、未成熟なエコで無理をするのはリスクが高い、コスパが悪い。
2. 2018年に機械学習フレームワークで起こったこと
機械学習フレームワークでも栄枯盛衰が激しいです。
2.1. Therano開発終了
正確には、2017年後半に開発終了のアナウンスがされました。
Deep Learning をPythonでやろうとした場合,Theanoしかなかった
私がTheanoの学習を始めたのが2015年でしたが,その頃の状況は,「やっぱりTheanoが"Defo"(default)でしょう」という感じでした.
たかだか、2-3年の話です。
2.2. PyTorchの台頭 FROM RESEARCH TO PRODUCTION
PyTorchが台頭してきて、ver.1.0がリリースされました。
のブログ記事がわかりやすいですが、画像も引用させて頂くと、
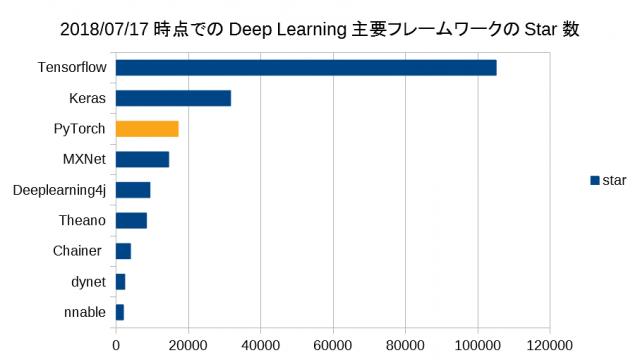
2017年頃から台頭してきていたらしいですが、現在、第三位、おそらくもうすぐKerasを抜いて第二位になるんじゃないでしょうか。
PyTorchはその習得のしやすさや、研究開発との親和性の高さから、発表されてすぐに世界中で人気になりました。
とありますが、PyTorchの謳い文句である、"FROM RESEARCH TO PRODUCTION"の通り、研究開発と親和性が高く、しかもディプロイして実用に耐えると。GPUのサポートはTensorFlow以上にピカイチっぽいです。
Therano無き今、機械学習界隈の研究の後継はPyTorchぽいです。
2.3. TensorFlow.jsの登場
2.4. TensorFlow 2.0への「破壊的」アップデート
ポイントはコレです。
TensorFlow Advent Calendar 2018を見ていると勉強になりますが、
Eager Modeをデフォルトで採用するPyTorchの使い勝手の良さが注目されていることもあり、長らくデフォルト化し続けてきたGraph ModeからEager Modeへのデフォルト化に舵を切ったのでしょう。
強化学習におけるTensorflowの実装たるや、その多くは可読性が低いです。それに比べて、PyTorchやchainerといったDefine-by-Run型のフレームワークの実装は読みやすく作りやすい。しかし、その時代もEager Modeの出現により終わりました。
3. ちゃぶ台返し再び
前回のエントリで、TensorFlowが最初出たときに思ったのが命令型パダライムのAPI使いにくい、という不平不満を書いていましたが、それはこの辺のことで、TensorFlow2.0になってデフォルトで「かなりマシ」になると解釈しています。
前向きに捉えれば、もちろん改善ですが、メジャーアップデートというのは根源的な破壊的変更を意味するわけで、これまで蓄積されてきたTensoflowのコード資産は、2019初頭にリリースされるらしい2.0では通用しなくなるでしょう。
特にこれから本格的に機械学習はじめたい、という学習者にとってはTensorflowは急転直下、使いにくいフレームワークとなるはずです。何故なら、既存のチュートリアルはすべて1.*ベースで書かれており、巷のTensorFlow入門記事もコードも当面2.0互換で出揃うには相当なタイムラグが発生するはずです。
コピペしても、バージョン違いでコードが動かないというのは大変作業効率が悪いもので、いちいち手直しする羽目になるでしょう。
4. Tensorflow.js もちゃぶ台返しされる
「TensorFlow本体とTensorFlow.jsのサーバーサイドの等価性を高めていく」というポリシーもあり、Tensorflow.jsもTensorflowベースなので、当然影響を受けます。
5. なぜ結構強めの主張ができるか?
昨今、ライブラリ、フレームワークの選択する際に、Web上に情報が豊富にある、というのは生命線だと思います。
実際に、Tensorflow.jsなら、ちょっと本腰入れてやってみるか・・・と甘い気持ちでやりはじめましたが、状況は極めて厳しくめちゃくちゃ苦労しました。
たとえば、とりあえず、MNISTの一番単純なNNならトレーニング時間と精度はどんな感じか?とやろうとしても見つかるのは、CNNのコードだけだったり、そもそも,TensoflowのいわゆるGraphModeとEagerModeのコード資産(その多くは、GraphMode)で混乱する、本家と.jsの混在もあるし、なかなか本質的なところまでたどり着けません。
その折、Tensorflow2.0で破壊的変更がある、となったので、ああこれは無理だな、と。
関数型プログラミングVSオブジェクト指向みたいな議論もそうなんですが、パラダイム、根底となる考え方の違いというのはとても重要です。
6. PyTorchにしたら一瞬で問題が解決した
前提として、
-
VisualStudioCode のPythonツールやらでPython書いたら、なんか自動でインテンドもしてくれて、普通にPython書けるようになった。
-
constとかないのが気持ち悪とか思っていたが、つーかそもそも、関数型にあまり興味ないぽいPython界隈のイミュータブル事情ってどうなってるの?と思いたまたま読んだ Pythonの、変数と代入についての誤解を解くで、誤解が解けた。
Python普通に書けるな、と思って安心して、PyTorchで情報探すと、とりあえず「根本の思想が一貫している」ことから、コード資産の分散がなく、やりたいことの本質へすぐにたどり着けるようになりました。
加えて、JavaScriptで関数型プログラミングやるレベルの人なら、おそらくTensorFlow/.jsのフレームワークによる過度の抽象化というか、粒の大きさは、なんかただ、コードをコピペしているだけのようで、まったく勉強にならない危険性が大きいです。もちろん低層のAPIへ降りて、といくらでもできるんでしょうが、ここで一気にコード資産が減る、情報が見つからない壁にぶちあたるでしょう。
それに対比するように、PyTorchは、APIの粒が適度です。Pythonに根ざしているとアピールもされているようですが、抽象度の高すぎるフレームワークに組み入れられすぎることもなく、ちゃんとプログラミングできる感じ。
研究者がPyTorchのほうを好むというのも普通に合点が行きます。
7. PyTorchでも関数型パラダイムは未成熟

これはMNISTを学習する典型的なCNNですが、図の一番左でINPUTされる画像(図のAとかいうのは間違いで本来は数字の画像)ベクトルから一番右へ0−9の10個の数字へ分類するOUTPUTをもつ巨大な関数です。
NNの各レイヤ、それから活性化関数(ReLuとか)はそれぞれ関数で、合成関数となっています。
NNのレイヤの素子は線形(アフィン変換 y = Wx + b )ですが、各レイヤはその合成で非線形となっているので、各非線形関数を各々カーブフィッティングさせながら、全体の合成関数もカーブフィッティングするという問題に他なりません。
ネットワーク定義のコードを見ると、
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)といった感じです。これでもTensorflowが最初にリリースされてから長らく台頭してきたGraphModeで書くよりもずいぶんスッキリしているのですが、ずいぶんモッサリとしたコードが公式チュートリアルのサンプルコードとして提示されています。
見ればわかるとおり、クラスの中でわざわざ self.conv1 とか定義して、それを自身の foward メソッドをもってミュータブルな x の連鎖とともに消費する、という、まあ関数型プログラミングに慣れた人たちにすれば、「ないなこれは」というコードが提示されています。
これはCNNで計算時間が大きいので、手を汚してはいませんが、別のもっと単純なNNでは、こういうNNの設計は、PyTorchでも、
net = nn.Sequential(nn.Linear(4, 10),
nn.ReLU(),
nn.Linear(10, 8),
nn.ReLU(),
nn.Linear(8, 3))こう書けます。
何をやっているのか?というと、単に各レイヤの関数を並べて、それを nn.Sequential で合成しています。
f3 = compose(f1,f2) とやっているのと等価です。
部品としてのNNの筋の悪さについては、繰り返し、前回のエントリ JavaScriptによる機械学習の未来(TensorFlow.js)と関数型プログラミングで触れましたが、関数である、という視点を強く持てば持つほど、これがNNである必要はまったくないというのは明らかです。
8. 結論らしきもの
あと2年くらいは、特に初学者はTensorFlowでやると同一フレームワーク内のパラダイム混在による混乱で苦労するだろう。2.0以降では、1.*系のコードは大幅な手直しなしでは役に立たない。
TensorFlow.jsもその煽りを食う。
大幅な手直しを迫られるくらいなら、パラダイムに統一性がある今一番勢いのあるPyTorch使うのが100倍賢い。
今のちゃぶ台返しが著しいプログラミング界隈では、3-5年スパンでは、JavaScriptが機械学習のメインストリームになる可能性は小さくないが、大きいとも言い切れない。
関数型プログラミングではJavaSciptエコのほうがPythonエコよりもずいぶん成熟しているように見える、というか、TensorflowのAPIにせよ、PyTorchのサンプルコードにしろディープラーニングは関数を合成している、という視点がまるでないようにしか思えない。
総体的なコーディング力はJavaScriptエコのほうが人口もあわせて考えると多分上。裾野も広いので、長期的には取って代わったほうが人工知能研究のためにも良いように思える。歴史的な経緯以上にPythonの優位性、Pythonでなければならない合理性というのは存在しないが、Pythonもけして悪くはなく、JavaScriptへの積極的な置き換えを訴求する決定打には欠ける。
どうなるかわからないので、3−5年後に勝馬に乗るほうがいい。短くも長い期間なので、素直にPythonとPyTorchをやったほうがいい。







0 件のコメント:
コメントを投稿