JavaScriptによる機械学習の未来(TensorFlow.js)と関数型プログラミング
今から3年も前になるが、2015年末にGoogleが TensorFlowを発表したとき、率直な感想は「ああまたこんなものが出たのか・・・」だった。
そもそも自分の好きなプログラミング言語として、
1位 JavaScript/最近では特にTypeScript+VisutalStudioCodeの支援が驚異的
2位 Haskell 理論寄りの話題には事欠かないから
といった感じ。
PythonはSTEM(科学技術分野)でデファクトスタンダードであり、数学、確率統計、機械学習のライブラリもコード資産も情報も豊富でやったほうが良いとはわかっており、食わず嫌いは良くないとも思い好きになろうとしたが、バージョン2と3の互換性が致命的になくて苦労したり、まあいろいろな理由で結局好きにはなれなかった。その頃ちょうどJavaScriptがES6に進化し、特に関数型プログラミングでの記述力表現力が飛躍的に向上していたし、TypeScriptの登場、Reactの登場、AtomEditorの登場とJavaScript界隈もそうとう賑わっていた時期と重なったというのも大きい。今でもろくにPythonのコードは書けないだろう。
TensorFlowも例に漏れずPythonベースだったので、ああまたか、でもメインストリームだから仕方ないか、という諦めの感想と同時に、しかしPythonがJavaScriptも含め他の言語より殊更優れているようにはどうしても思えないのに、ただ単にいつもの歴史的偶然からSTEMのメインストリームになっていることについては不条理感と不満はあった。いつも思うのだが、このSTEM界隈で必然性や合理的理由に欠ける大勢による後追い現象はろくなものはないと思う。
基本的に自分の機械学習への取り組みについては熱中したり熱中しなかったりで普通に2,3年いや3,4年の周回遅れをとっては、また熱中して最先端に追いつこうみたいな繰り返しだ。さすがに3,4年も周回遅れだと、ありがたいことにその期間にそれなりのブレークスルーもあって面白い。逆に言うとそれくらい寝かさないと情熱が続かない程度にしか機械学習にコミットしていないのだけど、根本的にしっくりこないことが重なり興味と情熱が下火になってしまう。
根本的にしっくりこないこと、というのはどういうことか?
ディープラーニング、深層学習というのは、細部の関数の学習から、その各々の関数の合成(Function Composition)を繰り返して、なんかのn次元ベクトル空間に潜在している多様体を特定する作業に過ぎない。YouTubeで見た著名な研究者によるプレゼンでもそう発表されていたし、結局これまではCPUのパワー不足により、そういう多層の関数合成には至らなかったんだな、ということはおおよそ明らかになっている。
この辺の理論的土台が一旦しっかりと固まれば、あとは関数合成なんだから、理論面に秀でた情報科学者やプログラマーが加速度的になんかすごい仕事をするはずだし、近い将来必ずそうなるとは思う。しかしまだ夜は明けていない。
日本語版Wikipediaやその他一般向けの記事でのディープラーニングの紹介では、ひたすら、多層のニューラルネットのことだと強調されている。ニューラルネットがディープなのだと。
たしかに、ヒントン先生らがディープラーニングのブレイクスルーを巻き起こしたのは、多層のニューラルネットだったし、現在も実績を残しているのはほとんどニューラルネットだけれども、今の流れは単に過去の実績に依存する壮大なる後追いで、多大に偏向した人的リソースの投入と、職人技の連鎖に依存していると思う。
ディープニューラルネットの最近のブレイクスルーは、府大生が趣味で世界一の認識精度を持つニューラルネットワークを開発してしまったの元となる、Residual Network(ResNet)があると思うのだが、リンク先や数々の情報を参照するにつけ、チューニングに次ぐチューニングで、こういう問題があるからとりあえずこうしてみたら成績が向上した、というようなトライアンドエラーによる職人技の集積であって、その凄さと実績は素直に感嘆しながらも、これらの膨大な努力はニューラルネットが抱える根本的な問題をまったく解決していない応急処置みたいなものにすぎないので、優秀な頭脳がもったいないなあ、と毎度思う。
ディープラーニングの生い立ちがニューラルネットに深く根付いている事実は歴史的事実だけれども、最先端の研究でここまでニューラルネット一辺倒にやる必然性と合理性はとても見いだせないし、知的人的リソースの膨大なる浪費だと感じる。
念の為だけれども、Wikipedia日本語版やら一般向けのいい加減な技術紹介記事のディープラーニングの定義は仕方ないとしても、著名な研究者(Yoshua Bengio先生ら)によるモダンな教科書などでは、ディープラーニングとはニューラルネットに限定されたものではないということがそれなりの文面を割いて書かれてある。
1パラグラフだけ引用すると、
The modern term “deep learning” goes beyond the neuroscientific perspective on the current breed of machine learning models. It appeals to a more general principle of learning multiple levels of composition, which can be applied in machinelearning frameworks that are not necessarily neurally inspired.
現在の機械学習モデルにおける、モダンな用語としての「ディープラーニング」は、神経科学の視点を超えています。複数レベルのコンポジション(合成)を学習する、もっと一般的な原理をアピールしているのであって、必ずしもneurally inspiredのものではない機械学習フレームワークに応用できるものです。
ニューラルネットがかつては一世風靡していた過去の遺物に一向になる気配もなく、若手も含めて研究者をここまで非合理的に取り込む理由はなんだろうか?しょうもない仮説を建ててみると、
1.とりあえず機械学習の歴史的発展経緯から、いろはの「い」として最初に教えられる。メディアでもなんでもこれがディープラーニングなんだ、と信じて疑わない状況に染まってしまっている。
2.現在も大多数が活発に研究しており、興味深い成果が出続けており、絶賛ブレイク中で将来も有望の分野に見えている。
3.とりあえず本質的側面、小難しい理論面に切り込んで開拓せずとも、ニューラルネットという「モノ」が転がっているので好き放題遊びやすい。手軽。
TensorFlowについても、まずとりあえずニューラルネットだ、とまるでニューラルネットを組み立てるためにあるフレームワークだみたいなプレゼンスであったし、ああまた手軽なおもちゃのパフォーマンスチューニングで遊ぶだけで、根本的、本質的な研究をおろそかにする若手研究者を量産する種になるのかねえ、とウンザリしたのでした。
自分は特に関数型プログラミングをするので、部品の粒の大きさとか品質とかを気にする。これは何らかの本質的意味がある堅牢で良質な部品で、今後の関数合成の基盤として有用である、とかそうではない、とか。ひとつ前のエントリの30分でわかるJavaScriptプログラマのためのモナド入門でも、結合法則を満たすモノイドが良質な部品で、モナドも良質な部品で、ES6+Promiseはその観点から行くとちょっと筋が悪いなあ、とかそういう事を書いたつもり。
広く採用される部品となる関数は、歴史的経緯や大勢の後追い以上の堅牢な品質が担保されて然るべきだと信じるし、それは機械学習、ディープラーニングの部品にも当然適用されるべきだと思う。現状自分は、ニューラルネットがその部品たる資質があるとはまったく思っていない。
そもそもPython界隈は、昨今のJavaScript界隈のような関数型プログラミングへの目覚めというか賑わいをまるで感じない。それは偏見かもしれないが、とりあえずPythonベースのTensorFlowのAPIというよりフレームワークの実装そのものを眺めてみても、ゴリゴリの命令型パラダイムで設計されており、ああやっぱそういうことは気にしない感じで行くのね、ディープラーニングは本質的には関数型プログラミングなのに・・・と。それが当時がっかりした理由だった。
ごく最近、ディープラーニングと関数型プログラミングを結びつけて論じている人いないかな、と検索していると、Neural Networks, Types, and Functional Programmingという記事が見つかった。すでに3年以上前の記事なので、こういうところで周回遅れぶりを痛感する。
現在のニューラルネットは若く未成熟な分野で「アドホック」つまり具体的過ぎて十分に抽象化されていない、統一的視野も理解もない、30年後にはもっと違った視点を我々は獲得しているだろう、というような内容。それから、具体的に著名なニューラルネットモデルを列挙して、それが如何に関数型プログラミングの部品に対応しているのか?ということを例証している。
コメント欄でも、ヒントン先生の弟子でもありディープラーニングのブレイクスルーの立役者であるYann LeCun(コンピュータビジョン、特にCNNの仕事で有名)が参考になる論文を列挙してくれていたり、たいへん読み応えがある。元エントリを全文和訳!でもしたらこのエントリの価値も少しは向上するのだろうが、翻訳作業というのはものすごい時間と労力がかかるので、とてもそんな労力をかける気力はない。
基本的に日本のプログラマ界隈では「ポエム」(悪意、中傷からはじまった言葉だと認識している、現在は転じて自己謙遜を含む穏やかな意味にシフトしつつあるとは思う)とか言われるタイプの文章で、本人も「エッセイ」だとか、こういうのを論じるバックグラウンドはないので資格がないかもしれない、広く議論を呼びかけたいだけだとか、30年後はこうなっていてもおかしくないとか、謙虚というか予防線張りまくりなのだが、他のエントリも次に引用するとして素晴らしい洞察力をもった人物だと思う。
別のエントリ Neural Networks, Manifolds, and Topologyでは、タイトルの通り、トポロジーの視点を織り交ぜながら、ニューラルネットが多様体を特定するために具体的にどういう挙動をしているのか?というのが豊富なグラフィック(この人この辺がものすごいと思う)とともに丁寧に論証されている。つくづく思うのだけれども、もうこの分野での紙やらあと白黒のPDFの役割は終えたんじゃないだろうか?彼のこういう一連のエントリは高い代金の機械学習入門書以上の価値と品質がある。
具体的に例証した結果、Better Layers for Manipulating Manifolds? では、
The more I think about standard neural network layers – that is, with an affine transformation followed by a point-wise activation function – the more disenchanted I feel. It’s hard to imagine that these are really very good for manipulating manifolds.
標準的なニューラルネットワークのレイヤー、つまり活性化関数で処理するアフィン変換のことだけど、考えれば考えるほど、幻滅させられてしまう。これが多様体を操作するために本当に良いものだとは到底思えない。
と実質結論づけてしまっている。まあ完全に同意。ニューラルネット筋悪すぎ。
ということで、ニューラルネットが抱える問題などを改めていろいろ調べていると、東大の名誉教授で、情報幾何学(information geometry)という学問をつくった甘利俊一先生が居て、その枠組みの自然勾配法をやると、一般的な勾配学習よりも場合によっては収束が1000倍以上も速くなるとか書いてあった。
神 経 多 様 体 の 特 異 構 造
自然勾配法は何故数千倍も速いのだろうか.パラメータ の空間が ユークリッド空間なら,自然勾配法は通常の勾配 法と同じである.それなら,多少曲がっていても,自然勾配法と通常の方法でそれほどの差はないだろう.もし,シミュレーションが示すような驚くべき差 があるならば,この空間は極端に曲がっていること,いわばブラックホール のような特異点を含んでいるのではないかと考えられる. これは事実であることが最近の研究でわかってきた4).
と、とんでもないことが書いてあった。さらに検索すると(Googleは本当に便利である)
ニューラルネットワークによる学習の停滞はどこから生ずるかという見やすい記事があり、
今回はニューラルネットワークの学習における不思議の1つ、「学習の停滞」の原因について述べてみたいと思います。
まとめ
・学習の停滞と再開は鞍点によって生ずる
・鞍点は勾配が0になる点
・勾配が0になる点⇛パラメータを少し変更しても出力にまったく変化を及ぼさない点
・ニューラルネットには特異点という質の悪い領域が広がっている
と書かれていた。大まかな印象として、詰めの微妙な学習ほど難易度が高くなる、というのは直感的に理解できるとしても、たしかにニューラルネットの学習の収束はいくらなんでもあまりにも遅すぎるというか不安定な挙動が顕著だというのは大多数が痛感するところではないだろうか。
情報幾何の枠組みの自然勾配法をもって、まあワーストケースだろうけども1000倍も数千倍も高速になる!ということは、その裏を返せば、そもそもの特異点やらプラトーとも呼ばれる鞍点が多いニューラルネットというモデル選択自体が悪手なのだろうなと普通に思う。つまり、ニューラルネットではない他のモデルをベースにしていれば、そもそもそういう自然な高速化手法自体不要であろうと。
どうも数多くの職人技とも言えるニューラルネットのパフォーマンスチューニングや、本質的に関数合成であるディープラーニングのレイヤー以上に複雑なニューラルネットモデルの多大な構造は、この辺の致命的欠陥を覆い隠すための本質的には不必要な余剰なハックなんだろうな、というのが感想。あくまでエンジニアリングなのでトライ&エラーがあるのは当たり前だとしても、XXの欠陥をカバーするためにこうしたら良い結果になりました!というのが多すぎるように思うし、それによって今後の応用に耐える知見がどの程度もたらされるのか疑問。
ディープラーニングの多レイヤー化で、convolutional neural networks(CNN)は本質的だと思う。ただしこの中間のN(neural)については、実際に成功を収めた具体的な実装がニューラルネットだったとしても、本質的にニューラルネットである必要はない。同じブログでは、ニューラルネットなしで、convolutionsというのはいったい何なのか?というのが解説されている。
コンピュータビジョンのディープラーニングで、convolutionalであれば、別にその「素子」がニューラルネットでなくても性能を発揮するという事例は検索するとすぐ出てきた。
PCA(主成分分析)ベースのConvolutional Network。さすがにえ?ただのPCAなの?と思ってしまうが、結果はものすごい。要するにConvolutionalのディープラーニングがすごいのであって、ニューラルネットはむしろどうでもいいという証左。
このモデルの特徴は、
-
非ニューラルネットのConvolutional Network
-
unsupervised(教師なし学習)
-
教師あり学習のときの back propagation がないので効率的
-
"Dropout"だとかファインチューニングに依存しない
効率的ということだが、Back propagationもないただのPCAで構成されたディープラーニングと、既存のCNNの学習速度の差は圧倒的だろうと思うわけだが、実験結果を見て一番すごかったのは、texture datasetで、PCA-Based Convolutional Networkが、251.80秒の学習で99.89%の精度を出した一方で、トラディショナルなCNNは、10時間で50000回の学習で43.2%の精度しか出ず、その後過学習になって精度が悪くなっていったという。
PCAは研究されつくされていて理論的にも正体は知れている。もちろんPCAの他にも次元削減の方法はたくさんあるが、特徴量の抽出という意味ではこれほど率直で基本的な方法はないとも言える。ニューラルネットのように、いや実は、ブラックホールのような特異点がいくつもあることがわかってプラトーもあって、とか恐ろしい隠し玉は存在しない。速度はもちろん圧倒的だ。
TensorFlowのディープラーニングTutorialページにもお手軽にCNNを構築してテストできるというのがあるが、本来我々が優先して学んだり実践すべきなのは、こういう正体と挙動がよく知れたPCAが部品となっているディープラーニングなのではないだろうか?
NNでないのならやってみたい、素直なPCAならむしろディープラーニングのHelloWorldとして実装してみたい、と思う。そこで、今年4月くらいに出てきたTensorFlowのJavaScript版であるTensorFlow.jsだ。
本質的に関数合成のディープラーニングなのに、TensorFlowに満ち溢れる命令型パラダイムの強烈な違和感というのは、不思議なことにJavaScriptのテリトリーに入ってきたら、多分なんとでもなると思ってしまう。NNに関する一切合切のAPIはガン無視するか、レガシーなモデルとの比較対象のためにあると考えれば整合性もつく。個人的には、機械学習と相性の良い数値計算ライブラリ+学習・テスト用データセットのDL展開ユーティリティ+テストWeb出力のUIライブラリと考えている。
実際に現行のJavaScriptエコは関数型プログラミングへの進化圧はかなり強烈なので、Pythonエコではおそらく生まれなかっただろう機械学習、ディープラーニングの関数型プログラミング化という一大ムーブメントが起きないだろうか?何か大化けしないだろうか?と期待している。
道具立てさえ揃えば、研究者、開発者、学生には選択肢が増える。JavaScriptのコミュニティは現状圧倒的なので、STEM領域全部とは言わないまでも、少なくとも機械学習の分野でPythonを割食ってしまう流れになる可能性は小さくない。自分のように、ああPythonかあ、と思っている開発者が実際どの程度の割合いるのかは知らないが、単純に頭数は非常に多いだろうとおもう。特にTypeScriptとVisualStudioCodeの支援がある開発環境など、今のJavaScriptの開発効率の高さに満足している人たちはPythonを使わなくても同じことができるのならば、わざわざPythonを選ぶ合理性はないと思う。
ここで問題となってくるのがスピード。パフォーマンスだ。そもそもディープラーニングのブレイクスルーを果たしたのは、昔には存在しなかった現代のコンピューティングパワーのおかげなので、ここは肝だとも言える。
Pythonの強みは、numpyみたいな数値計算ライブラリがあって、しかもその実体はCかC++でコンパイルされたバイナリで、重い行列計算(PCAなんかもろにそれ)は、実質ネイティブコードとして高速に処理されてしまう。しかもGPUが使えればそっちでさくっとやります、という完全なチートレベルなので、もうこうなるといくらJavaScirptでMath.jsだ、なんだの言っても、戦闘力が違いすぎてお話にならなかった。そういう状況が今まで続いてきた。
TensorFlow.jsは、WebGL経由でGPUパワー使います、というのがひとつのウリだ。しかし、FAQを見ると、
How does TensorFlow.js performance compare to the Python version?
In our experience, for inference, TensorFlow.js with WebGL is 1.5-2x slower than TensorFlow Python with AVX. For training, we have seen small models train faster in the browser and large models train up to 10-15x slower in the browser, compared to TensorFlow Python with AVX.
WebGL使っても、jsのほうが2倍くらい遅い、15倍くらい遅くなることもある、とかかなり残念なことが書いてある。これは致命的だ。
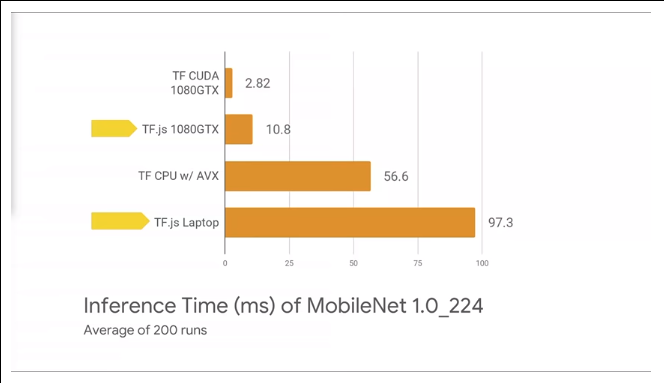
TensorFlowでMobileNetをやったときに、Python+CUDA(GPU)とJavaScipt+CUDAだと3−4倍の開きがある。GPUはスピードをカネで買っているで、こういうのは受け入れられないと感じる人がほとんどだろう。
しかし、よく考えてみると、そもそもPythonは、バックエンドとしてC/C++のバイナリを持っているだけなので、JavaScript であっても、ブラウザ+WebGLのパターンではなく、node.jsならば同じことは可能なので、Google IO 2018で、そうしました、と発表された。
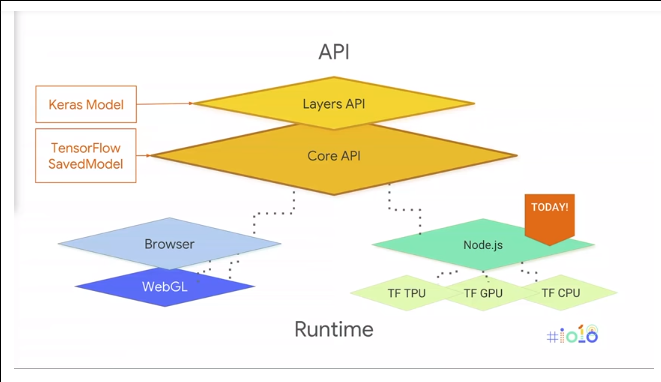
tfjs-node-gpu 1本落とすだけで、既存のコードがノードでGPUで動く。
TensorFlow.js(Node)のバックエンドで動いているのはTensorFlowのPythonが使うC++バイナリと同一なので、理論的には同じパフォーマンスが出るはずで、ほぼそのとおりになっている。
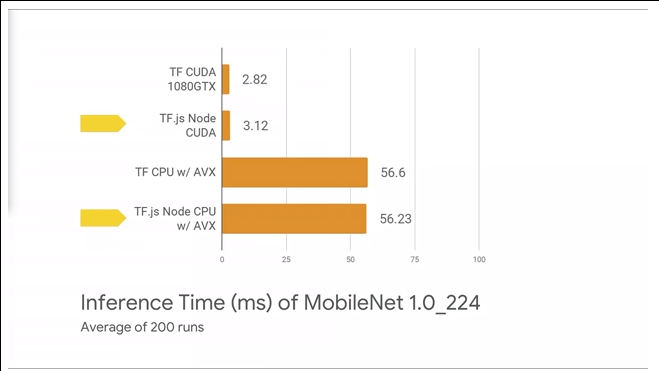
スピードのことを更に言うと、GoogleIOの動画でも言及されていたが、昨今のJavaScriptのスピードはとんでもなく速い。正確に言うと、この場合NodeのエンジンであるV8の開発元はTensorFlow.js(Node)の開発元のGoogle自身で、ふんだんにカネをかけて全力で開発しているので速い。Pythonの10倍速いと言っていた。
要するに、今現在、機械学習のパフォーマンスで、JavaScriptがこれまでSTEM業界を席巻してきたPythonに徹底的に劣るという懸念事項はもう完全になくなったと言えるし、TensorFlow.jsとV8の開発元が同じGoogleであるということを考えると、今後その気になりさえすれば、いくらでも最適化する余地はあるだろうから、JavaScriptのほうが有利だとも言える。
JavaScriptの重い数値計算がネイティブコードで動くようになった、というのは非常に大きい。
JavaScriptは機械学習のメインストリームになりえるだろうか?
今回はあえて、テーマに首尾一貫性がない感じにしてみました。

0 件のコメント:
コメントを投稿